Editor’s Note: The following post is taken from the Q&A session of IntegriChain’s ‘Patient Tokenization: The Secret to a Smooth Patient Journey’ webinar. Afaque Amanulla, Director, Industry Solutions – Patient Access, led the presentation. Afaque’s responses have been edited for clarity. Click here to view the full webinar recording.
Q: What data sets do you typically see that manufacturers use to build out patient journey analytics?
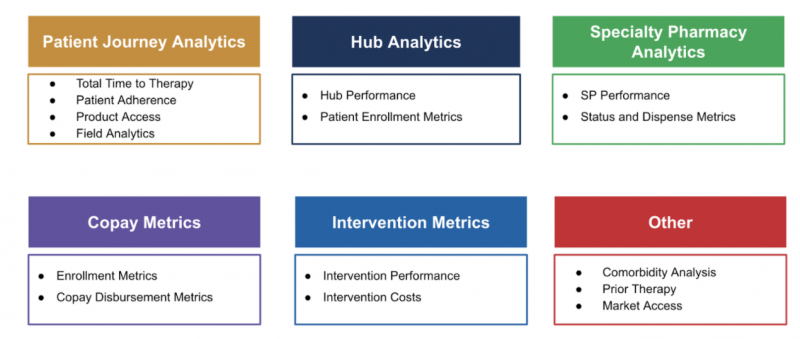
A: We typically work with specialty pharmacy datasets such as status and dispense datasets, hub status, reimbursement support datasets from hub, and co-pay datasets that show the co-pay disbursement and enrollment activities. We also see enhanced patient services, which are essentially intervention data sets that show the interaction between a specialty pharmacy provider that is providing an enhanced service including things like reminder or welcome calls, welcome kits, nurse training, and so on.
As therapies begin to evolve, we also see an uptick in less standard datasets: things like syndicated claims data that is used for payer therapy analysis, commodity analysis, or competitive landscape analysis. With the rise in these less standard datasets, we’ve begun building that into our data aggregation. Less commonly, for therapies such as buy-and-bill products, we’re also seeing things like IDN dispenses and physician practice dispenses. Claims data is also very good for giving a patient 360 view about what kind of other medications or therapeutic areas that the person is experiencing. EMR helps with the comorbidity analysis, in addition to the bridge support and patient assistance programs that also come into play.
Patient ID datasets are used to derive insights across many areas, such as:
Q: How do you see the risk of de-identification guidelines impacting the ability of analytics to be completed by connecting disparate tokenized datasets?
A: The de-identification process is based on the expert determination method. We look at it and if there’s any risk of exposing PHI, we address it so that patient privacy and regulatory compliance is maintained. The good news is, a majority of the time there’s a risk there’s also a solution to that risk as per HIPAA. Certification must be done manually on a periodic basis by a status sequence expert.
From a data aggregator perspective and from someone who provides certain out-of-the-box analytics on these patient use cases, we manage this risk by having our out-of-the-box use cases and data sets undergo periodic review to make sure that they are not causing reunification risk for a general set of therapeutic areas and patient populations. If you move away from these out-of-the-box analytics and move toward more custom analytics – and depending on the size of the patient population – you would have to do this review every time to maintain compliance.

Q: Besides the patient tokenization issues you previously mentioned such as false positives and negatives, what are some of the other challenges you’ve encountered and how have you addressed them?
A: All of this boils down to data quality challenges. For example, false negatives actually happen because of data quality issues during the data validation and data quality processes. Some of the things we see now is the inconsistent reporting from some of the data providers as well as inconsistent ways of trying to rectify problems that they’ve had in the past. So when we identify a problem, we will work with the data provider to get it resolved and get record(s) restated. One of the challenges is really the back and forth between us and the data provider, making sure we’re very clear on how they’re sending us the data. Does the data that they’re sending fix the original issue? That’s why establishing good relationships with the data providers is very important, and we continue to work towards improving those relationships in order to get the best possible outcomes for our customers.
Q: Does tokenization service essentially lock us to a vendor forever? Is it transferable?
A: There are certain data providers that are proprietary, so it’s within the best interest of the manufacturers to do their due diligence before making a selection. I would suggest looking into vendors that are more independent or commonly accepted among the industry that wouldn’t lock you in so you can change the data aggregator or vendor more easily. When meeting with a new vendor, some have strong preferences toward one de-identification tokenization partner over another, so it’s important to understand the total landscape for the use case you’re trying to accomplish. We’ve worked with a number of vendors over the years and there are industry trends in this particular area. You need to be clear about not only where you are now, but where you’d like to be in the future. That will help you determine which tokenization partners and vendors can help you get there.
If you need to move tokenization partners, that will require a one-time mapping exercise that you will have to do between the existing tokens and the new data provider tokens. The process is very similar where you have enough contextual information and identifiers to do that one-time mapping. Once you have that in place, it becomes the master data that can help you align the future sets of data with your new vendor.