


Editor’s Note: This is the second article in a series focused on how applying advanced data science techniques to patient access datasets can help manufacturers identify actionable insights and help patients start on therapy faster and stay on therapy longer.
Historically, the pharmaceutical industry has used a fairly standard set of Key Performance Indicator (KPI) reports and analytics to measure patient access. While these metrics are important, they describe patient access outcomes that are already known. Evaluating retrospective metrics is akin to conducting an autopsy to examine ‘what happened’. These insights can have an impact on future strategies and/or operational changes but they are not actionable in the moment. The industry’s focus needs to shift to much more proactive analytics that have the potential to positively impact any patient access already in progress.
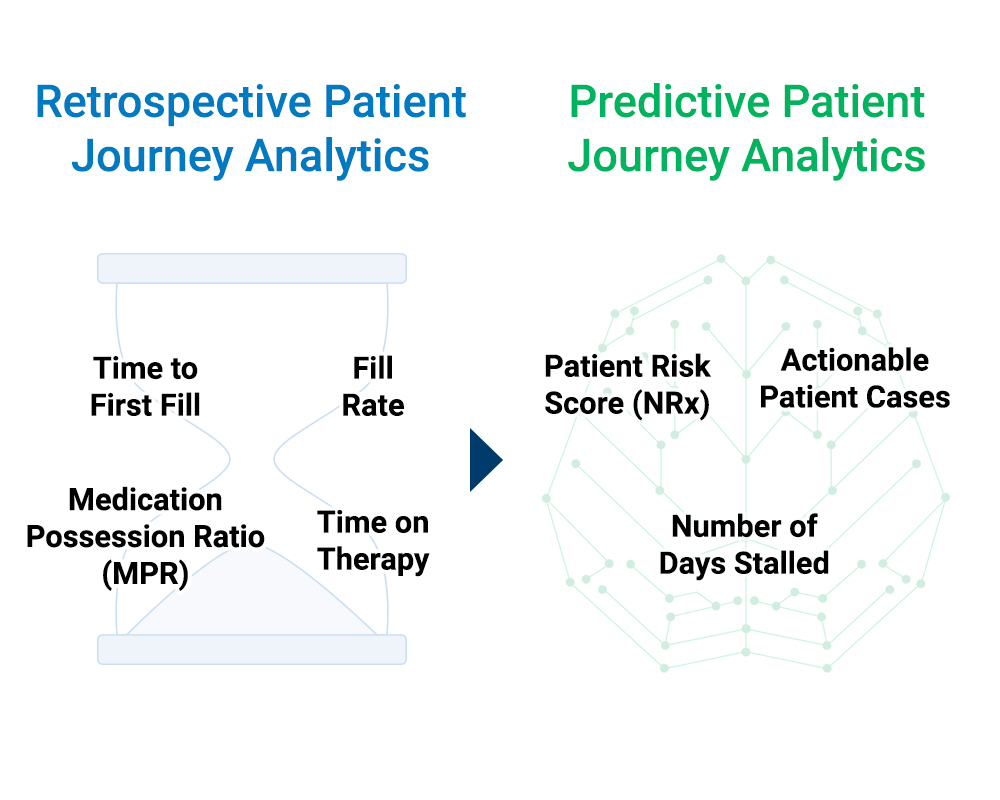
Figure 1: The ultimate goal for patient access analytics is to shift from a historically retrospective model to a much more proactive, even predictive, approach.
IntegriChain’s focus is improving patient access and adherence to therapy — everything after the script is written. That is, a healthcare provider (HCP) and a patient diagnosed with a specialty disease state have agreed to a treatment approach. The new patient now has a prescription and is being referred to a specialty pharmacy (SP). (Patients for certain brands are often referred to a reimbursement hub first and then referred to an SP). In an effort to save patient days of therapy, our patient journey analytics tease out the bad combinations of Payer, HCP, SP, and channel to assign a risk score to new patient referrals (NRx) as well as active patients.
IntegriChain is utilizing AI and machine learning to develop risk score models that will allow Field Reimbursement Managers (FRMs) and similar functions to proactively intervene on behalf of patients who are likely to experience roadblocks in their journey — before the roadblocks occur. Predictive patient access analytics look at analog patient cases and outcomes to understand the likelihood of a new referral experiencing an issue such as lengthy time stalled in prior authorization and appeal. These actionable insights allow an FRM to prioritize potentially challenging patient cases and work to resolve the anticipated roadblock.
Building Predictive Models with SP Patient Status Data
The primary data source for predictive patient access analytics is patient status data reported by SPs. These patient status records not only describe the steps patients have reached in their journey, they can contain additional information such as insurance benefit details, channel, diagnosis code, and out-of-pocket cost. The granularity of these records varies from SP to SP and is highly dependent on contract requirements and enforcement of those requirements. IntegriChain can also bridge patient status data to other relevant datasets such as dispense, copay, and population data, to engineer new features for predictive models.
It’s also worth noting that IntegriChain runs proprietary data cleansing and stewardship processes to enrich patient status data and make it more actionable. Enriched SP patient status data allows our data science team to train advanced machine learning algorithms to identify patterns and build mathematical models that can predict the likelihood that new or active patients will experience specific roadblocks (as defined by business users and disease state experts) in their patient access based on a library of historical cases.
Developing an Individual Patient Risk Score for Therapy Discontinuation
IntegriChain has deployed a random forest classifier that predicts whether or not patients who are currently on therapy are likely to discontinue before their next refill. Rather than representing the prediction as a binary variable (yes or no), the prediction is displayed as a number on a 0-100 scale. A higher patient risk score translates to a greater risk of discontinuation.
Individual discontinuation risk scores are assigned to all active patients (according to SP patient status/dispense records) and surfaced to IntegriChain’s ICyte platform. Key stakeholders such as Patient Services and FRM team leaders can then triage cases and prioritize interventions for patients with higher discontinuation risk scores. Our data science team has also deployed similar classification algorithms that generate individual risk scores (0-100) for patient initiation. When an SP receives a new patient referral, a risk score is generated and displayed in the ICyte platform.
Developing an Individual Patient Risk Score for Therapy Discontinuation
The old adage “garbage in, garbage out” is very popular in the world of data science and applies here. As was mentioned earlier in this article, IntegriChain uses a number of proprietary data science techniques to enrich SP patient status data and make it actionable. Patient status updates expected from network SPs are often missed (not received at all or delayed) or riddled with inaccuracies. IntegriChain is overcoming these data quality challenges by engineering thorough, elaborate data pipelines that cleanse, master and enrich the patient status data. These data pipelines master key fields such as payer and channel, cleanse inconsistently reported fields, and extract useful information from the status data and other relevant data sources to fill in incomplete and inaccurate patient access information. The result is a significantly cleaner patient status dataset that is ready for machine learning.






